统计学入门
统计、科学与观察
统计服务于两个目的
- 统计用于整理及总结信息,使得研究者看出在研究中发生了什么,并与其他研究者交流结果。
- 统计帮助研究者回答了引出研究的普遍问题,它根据获得的结果来确定结论究竟是什么。
统计指整理、总结并解释信息的一系列数学过程。
总体与样本
总体是在一个特定研究中所有感兴趣个体的集合。样本是从一个总体中选择出来的个体的集合,通常在研究中被期望代表总体。参数是一个值,通常是一个数字值,它描述了一个总体。参数可以从单个测量中得到,或从对总体的一组测量中推导出来。统计量是一个值,通常是一个数字值,它描述了一个样本。统计量可以从单个测量中得到,或从对样本的一组测量中推到出来。
通常,每个总体参数都与一个样本统计量相对应。
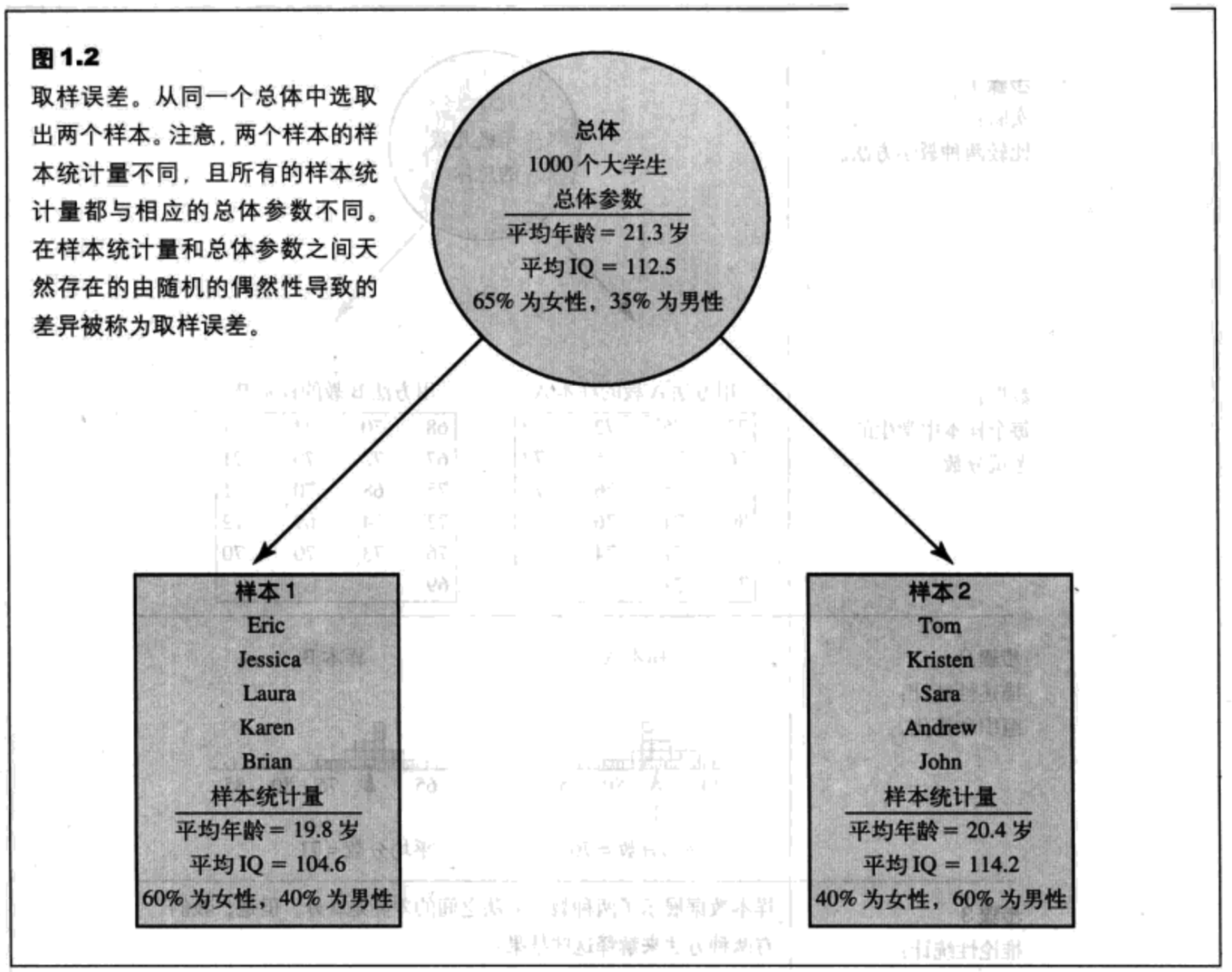
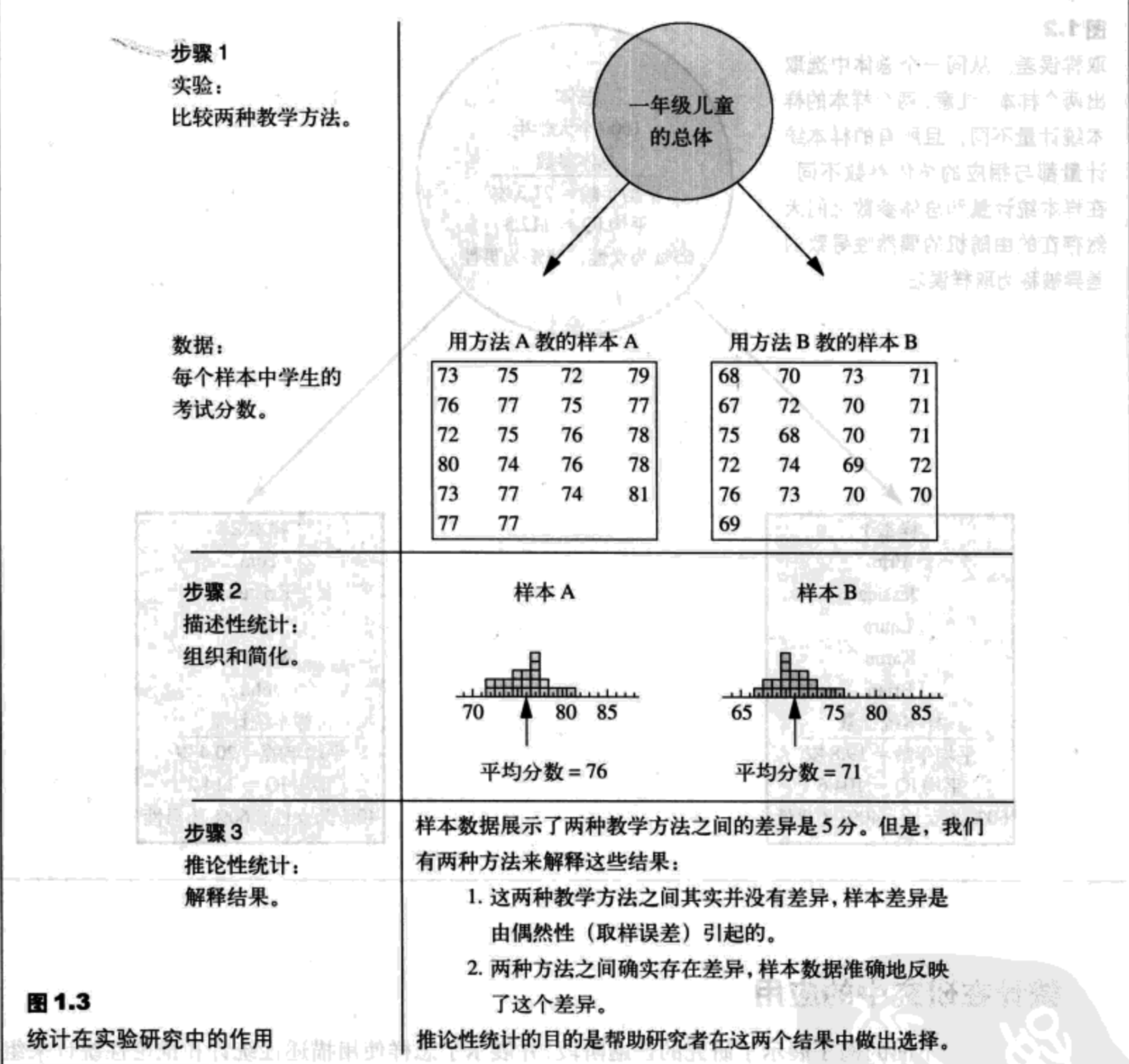
数据是测量或观察,它通常被称为一个分数或原始分数。描述性统计是用于总结、组织并简化数据的统计过程。推论性统计是允许我们研究样本,然后将研究结果推广至样本来自的总体的技术。取样误差是存在于样本统计量和总体参数间的差异或误差的数量。
统计在研究中的应用:

数据结构、研究方法与统计
变量是一种针对不同个体具有不同值得特性或条件。常量是一个特性或条件,它不会变化,并且对每一个个体都是相同的。
相关法
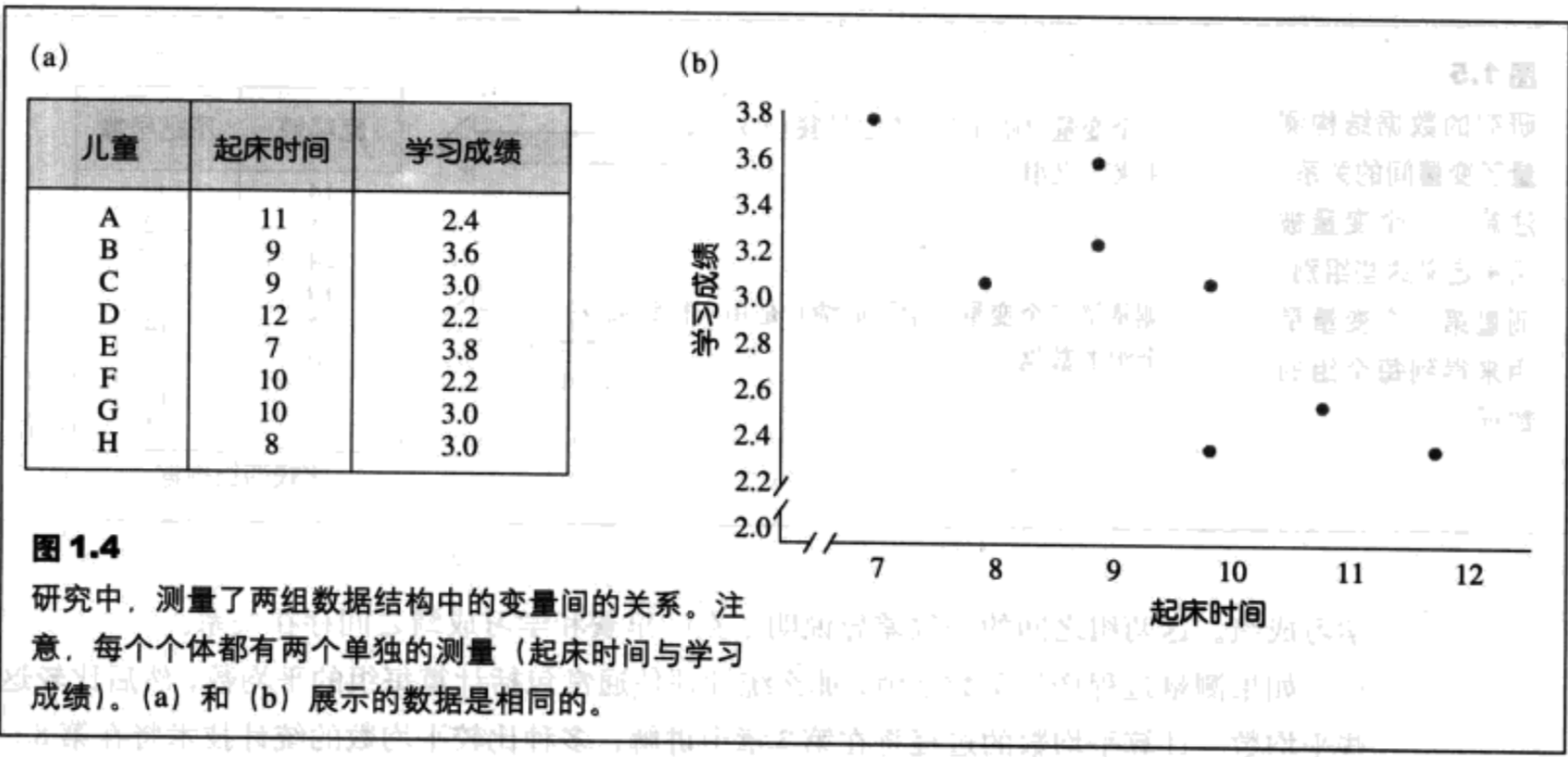
在相关法中,观察两个变量并确定它们之间是否存在关系。
实验法
一种比较不同组的分数的特殊研究方法被称为实验法。它有两个特性:
- 操纵。研究者操纵一个变量,将它的值从一个水平变化至另一个水平。然后观察(测量)第二个变量,来确定这种操纵是否导致了变化的产生。
- 控制。研究者必须控制研究情况,使得其他无用的变量不能影响需要研究的变量关系。

在实验法中,操纵一个变量并观察或测量另一个变量,为了建立两个变量间的因果关系,实验需要控制所有其他的变量,使它们不会影响结论。
实验法的术语
自变量是被研究者操纵的变量。在行为研究中,自变量通常由被试参与的两个(或多个)处理条件组成。自变量由在观察因变量之前就操纵好的“前”条件组成。因变量是被观察的那个变量,用于评估处理效应。控制条件中的个体不接受实验处理。他们或者不接受处理,或者接受一个中立的,安慰剂性质的处理。控制条件的目的是提供与实验条件相比较的基准。实验条件中的个体接受实验处理。
非实验与准实验法
很多研究对两个组进行了比较,但是,这两组不是通过操纵自变量得到的。相反,这些组通常由被试变量(如男性与女性)或是时间变量(如处理前与处理后)决定。在这些非实验研究中,决定组别的变量被称为准自变量。
变量与测量
构念与操作定义
构念是内部属性或特性,它不能被直接观察到,但是可以描述并解释行为。
操作定义是一个测量过程(一系列操作),它测量了外部行为,并使用测量结果作为定义和对假设的构念的测量。注意,操作定义有两个部分
- 它描述了一系列测量构念的操纵;
- 它用测量结果定义了构念。
离散变量与连续变量
离散变量由不同的、不可分割的类别组成。在两个相邻的类别之间不存在其他的值。
对于连续变量,在任意两个观察到的值之间都存在着无限多个可能的值。一个连续变量可以被分割为无限个小数部分。

实限是可以被表示为一条连续数据线上数值组成的区间的界限。将两个相邻数值分开的实限恰好位于这两个数值的中点。每个数值都有两个实限。上实限是区间的顶边,下实限是区间的底边。
测量量表
测量包括了将事件分类(定性测量)或使用数字描述事物的大小(定量测量)。
称名量表由一系列具有不同名称的类别组成。称名量表的测量将观察的对象分类并贴上标签,但不对观察做任何定量的分析。顺序量表由一组按顺序排列的类别组成。顺序量表的测量将观察的对象按大小排序。等距量表由排序的类别组成,这些类别都是完全相同大小的区间。在等距量表中,量表上数字之间的差异等价于量上的差异。然而,大小的比例没有意义。等比量表是一种等距量表,并且有一个绝对零值。使用等比量表,数字的比例可以反映量上的比例。

